반응형
Maven 프로젝트로 게시판을 짜던 도중 아래와 같은 오류가 발생하였습니다.

해결 방법 :
servlet을 찾지 못하는 에러로 해결 방법은 기존의 dependency 들의 버젼을 아래 그림과 같이 변경해주도록합니다.
pom.xml 의 spring 버전 3.1.1에서 5.0.0 으로 바꿔주었더니 해결이 가능하였습니다.

반응형
Maven 프로젝트로 게시판을 짜던 도중 아래와 같은 오류가 발생하였습니다.
해결 방법 :
servlet을 찾지 못하는 에러로 해결 방법은 기존의 dependency 들의 버젼을 아래 그림과 같이 변경해주도록합니다.
pom.xml 의 spring 버전 3.1.1에서 5.0.0 으로 바꿔주었더니 해결이 가능하였습니다.
인프런에서 김영한 강사님께서 진행해주시는 "스프링 입문 - 코드로 배우는 스프링 부트, 웹 MVC, DB 접근 기술" 과정을
들으면서 예제 소스코드를 따라하던 중 DB 연결 도중 아래와 같은 import 과정에서 오류가 발생하였습니다.


그래서 인터넷도 검색하고 하였지만, maven은 아래와 같은 방법으로 web.xml을 수정한다고 합니다.
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${org.springframework-version}</version>
</dependency>하지만, 저는 maven 형태가 아닌 grdle 형식으로 프로젝트를 생성하여 web.xml 을 찾을 수 없었다.
그런데 저와 같은 오류가 뜨는 분이 수강생분 중에 계셨고, 김영한 강사님께 직접 질문하여 해답을 받았습니다.
프로젝트의 'build.gradle' 의 파일의 내용에 다음과 같은 내용을 추가해주어야한다고 합니다.
해당 링크 참고 : https://www.inflearn.com/questions/98874
org.springframework.jdbc 패키지 import 오류 - 인프런
질문 - org.springframework.jdbc 패키지 import 오류 선생님~! 아래에 패키지를 import를 하지 못하는 오류가 발생하여, 질문드립니다. import org.springframework.jdbc.datasource.DataSourceUtils; 해결방법을 구글링하
www.inflearn.com
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
위 코드를 복사 붙여 넣기 해준 후 다시 실행 하였더니 문제 없이 해결 되었습니다.
* 혹시 위와 같은 과정을 진행하여도 안되실 경우 한번 껏다 켜주시면 정상적으로 작동합니다.
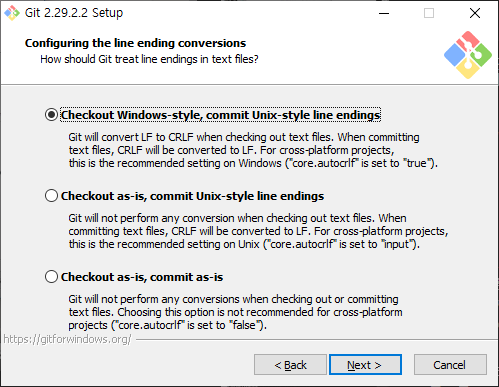
1) "File" 의 "Settings..."에 들어가줍니다.

2) Git이 설치되어 있는 경로를 잡아줍니다.

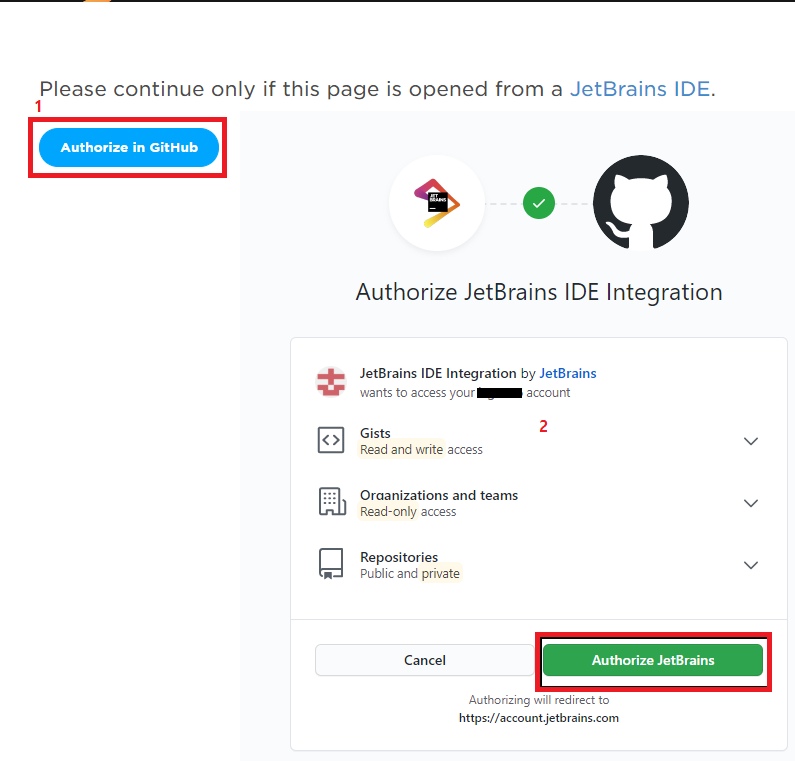
3) GitHub 계정 연동시키기

"Add Account..." 를 눌러 준 후 아래와 같은 과정을 진행해주도록 합니다.
4) 인텔리제이에서 만들었던 프로젝트명으로 깃허브에 리포지토리를 생성하여 업로딩


** 여기서 처음하시는 분들은 다음과 같은 오류가 뜰 수도 있다고 합니다. 다음과 같은 오류를 해결하기 위해서는

- ssh-heygen 으로 키를 생성
git bash 를 실행해줍니다.
$ ssh-keygen위와 같은 명령어를 입력 후 공개키와 개인키를 생성 할 수가 있습니다.
개인키는 자신의 컴퓨터에 보관하고, 공개키를 깃허브에 등록해서 인증해줍니다.

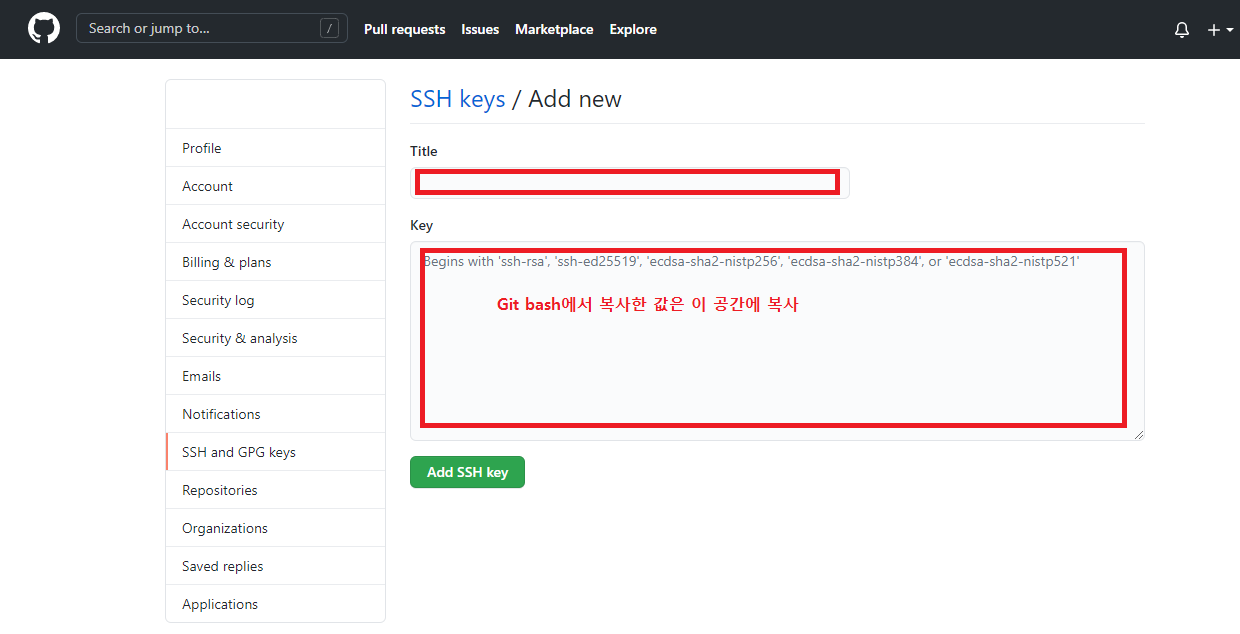
키가 저장된 해당 위치로 가서 키를 확인해줍니다.
$ cat 키가 저장된 경로
위와 같은 키가 쭉 나오면 ssh-rsa부터 끝까지 복사 하신 후 github ssh key에 등록해줍니다.
5) 이 과정을 거친 후 다시 처음부터 진행하면 정상적으로 올라가는 것을 확인 할 수 있습니다.
Git
git-scm.com












Numpy 배열 결합
# 배열 결합
print(x, end='\n\n')
print(y, end='\n\n')
arrhap = np.concatenate([x,y])
print(arrhap, end='\n\n')
x1, x2 = np.split(arrhap,2)
print(x1, end='\n\n')
print(x2, end='\n\n')
a = np.arange(1, 17).reshape(4,4)
print(a, end='\n\n')
x1, x2 = np.hsplit(a,2)
print(x1, end='\n\n')
print(x2, end='\n\n')
x1, x2 = np.vsplit(a,2)
print(x1, end='\n\n')
print(x2, end='\n\n')
# 출력 결과
[1 2 3]
[4 5 6]
[1 2 3 4 5 6]
[1 2 3]
[4 5 6]
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
[[ 1 2]
[ 5 6]
[ 9 10]
[13 14]]
[[ 3 4]
[ 7 8]
[11 12]
[15 16]]
[[1 2 3 4]
[5 6 7 8]]
[[ 9 10 11 12]
[13 14 15 16]]
1차원 배열인 x와 y 배열을 생성해줍니다.
arrhap 에 x,y 배열을 합친후 결과를 출력한 결과 1차원 배열을 리스트로 반환해주었습니다.
이것을 다시 x1과 x2에 split 함수를 사용하여 분리해주었습니다.
더 잘게 split을 사용할 경우 앞에 사용할 변수 명을 추가해준 다음,
split함수 옵션에 (나눌배열,나눌개수)를 사용해주도록 합니다.
a에 1~16의 숫자를 입력 후 4x4 행렬로 생성 후
hspit(나눌배열, 나눈배열그룹개수) : 지정한 배열을 수평(행) 방향으로 분할
vsplit(나눌배열, 나눈 배열 그룹 개수) : 지정한 배열을 수직(열) 방향으로 분할
저는 2그룹씩 분할을 하였기때문에 위와같은 결과가 생성됩니다.
| [Python] (7) Numpy 배열 행 열 추가 및 삭제 , 내장함수 (0) | 2020.06.15 |
|---|---|
| [Python] (6) Numpy broadcasting (브로드캐스팅) (0) | 2020.06.14 |
| [Python] Numpy (5) 집합, 전치 (0) | 2020.06.02 |
| [Python] Numpy (4) - 배열 연산 , 벡터 내적 (0) | 2020.06.01 |
| [Python] Numpy (3) - 슬라이싱 , 서브배열 (0) | 2020.06.01 |
# 배열에 행열 추가 삭제
import numpy as np
aa = np.eye(3)
print(aa, end='\n\n')
bb = np.c_[aa, aa[2]] # 열 추가 2번째 열을 하나 더 추가 후 출력
print(bb, end='\n\n')
cc = np.r_[aa, [aa[2]]] # 2번째 행 추가 후 출력
print(cc, end='\n\n')
a = np.array([1,2,3])
print(a, end='\n\n')
print(np.c_[a], end='\n\n')
print(a.reshape(3,1), end='\n\n')
# 출력 결과
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 1.]]
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]
[0. 0. 1.]]
[1 2 3]
[[1]
[2]
[3]]
[[1]
[2]
[3]]
eye 함수는 이전에 포스팅하였습니다!
2020/05/31 - [python] - [Python] Numpy (2) - zeros, ones, full, eye, 난수
[Python] Numpy (2) - zeros, ones, full, eye, 난수
2020/05/28 - [python] - [python] Numpy [python] Numpy Numpy 란? C언어로 개발되었으며, 계산을 위한 라이브러리로서 다차원 배열을 처리하는데 필요한 기능을 제공합니다. Numpy 데이터 타입 # numpy : ndarra..
lightchan.tistory.com
eye 함수로 3 x 3 행렬을 생성 후,
.c_ 를 사용하면 열을 추가한다는 의미로,
위 소스코드에서는 aa 배열의 열에 2번째 열을 추가해주겠다는 의미입니다.
.r_ 를 사용하면 행을 추가해주겠다는 의미로, 위 소스코드에서는 2번째 행을 aa 행렬에 추가해주겠다는 의미입니다.
a = np.array([1,2,3])
print(a, end='\n\n')
#b = np.append(a,[4,5])
b = np.append(a, [4,5], axis = 0)
print(b, end='\n\n')
c = np.insert(a,0, [6,7], axis=0)
print(c, end='\n\n')
d = np.delete(a, 1) # 1열 삭제
d = np.delete(a,[1])
print(d, end='\n\n')
# 출력 결과
[1 2 3]
[1 2 3 4 5]
[6 7 1 2 3]
[1 3]
append 함수 : 리스트의 맨 마지막에 값을 추가해주는 함수이다.
위 소스에서 a라는 1차원 배열 리스트에 4와 5를 추가해주었습니다.
insert 함수 : 리스트에 요소를 추가해주는 함수로 0 번째 위치에 6과 7을 더해준다는 의미입니다.
delete 함수 : 1차원 배열 a의 1열을 삭제한다는 의미입니다.
aa = np.arange(1, 10).reshape(3,3) # 2차원 배열
print(aa, end='\n\n')
print(np.insert(aa, 1, 99), end='\n\n')
print(np.insert(aa,1, 99, axis=0), end='\n\n')
# 출력 결과
[[1 2 3]
[4 5 6]
[7 8 9]]
[ 1 99 2 3 4 5 6 7 8 9]
[[ 1 2 3]
[99 99 99]
[ 4 5 6]
[ 7 8 9]]
aa라는 변수에 1차원 배열 1부터 9까지 삽입 후 reshape 함수를 통해 2차원배열인 3x3로 변경해주었습니다.
그리고, insert 함수에 axis 옵션을 주지 않으면 1차원 배열로 1번째 위치의 값을 99로 변경하는 의미입니다.
그 다음 출력문에는 axis=0 으로 행을 의미하며 1행 전부의 값을 99로 변환하는 의미입니다.
delete문은 insert 함수와 반대로 생각하시면 됩니다.
print(aa, end='\n\n')
print(np.delete(aa, 1), end='\n\n') # 0행 1열 값을 지움
print(np.delete(aa, 1, axis = 0), end='\n\n') # 1행을 지움
print(np.delete(aa, 1, axis = 1), end='\n\n') # 1열을 지움
# 출력 결과
[[1 2 3]
[4 5 6]
[7 8 9]]
[1 3 4 5 6 7 8 9]
[[1 2 3]
[7 8 9]]
[[1 3]
[4 6]
[7 9]]
ex = np.random.randn(5,4)
print(ex, end='\n\n')
print('1행의 합과 최대값')
print(np.sum(ex[0],))
print(np.max(ex[0],), end='\n\n')
print('2행의 합과 최대값')
print(np.sum(ex[1],))
print(np.max(ex[1],), end='\n\n')
print('3행의 합과 최대값')
print(np.sum(ex[2],))
print(np.max(ex[2],), end='\n\n')
c = np.zeros((6, 6))
print(c, end='\n\n')
num = 1
for i in range(len(c[0])):
for j in range(len(c[0])):
c[i][j] = num
num += 1
print('1~36 채우기')
print(c, end='\n\n')
print('2번째 행 전체 원소 출력')
print(c[1], end='\n\n')
print('5번째 열 전체 원소 출력')
print(c[:,4], end='\n\n')
print('부분 출력')
print(c[2:5,2:5], end='\n\n')
print('2-2번')
b = np.zeros((6,4))
c = np.random.randint(20, 100, 6)
for i in range(6):
for j in range(3):
b[i][0] = c[i]
b[i][j+1] = b[i][j]+1
print(b)
b[0] = 1000
b[5] = 6000
print(b)
print('3번')
ex1 = np.random.randn(4,5)
print(ex1, end='\n\n')
print('평균 : ',np.mean(ex1), end='\n\n')
print('합계 : ',np.sum(ex1), end='\n\n')
print('표준편차 : ',np.std(ex1), end='\n\n')
print('분산 : ',np.var(ex1), end='\n\n')
print('최대값 : ',np.max(ex1), end='\n\n')
print('최소값 : ',np.min(ex1), end='\n\n')
print('1사분위 : ',np.percentile(ex1,25), end='\n\n')
print('2사분위 : ',np.percentile(ex1,50), end='\n\n')
print('3사분위 : ',np.percentile(ex1,75), end='\n\n')
print('요소값누적합 : ',np.cumsum(ex1), end='\n\n')
# 출력 결과
[[-0.99017343 -1.26807787 0.61941937 0.40683047]
[-1.03161855 -1.23595668 1.54022423 -0.74237974]
[-1.55127342 1.67563386 -0.97895193 1.70391295]
[-1.23341949 0.09689477 -0.50175499 -0.63970651]
[ 0.17859581 -1.74168996 -0.8277483 0.23756665]]
1행의 합과 최대값
-1.2320014629208895
0.6194193744851698
2행의 합과 최대값
-1.4697307416436023
1.5402242284791654
3행의 합과 최대값
0.8493214631503689
1.7039129520342273
[[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
1~36 채우기
[[ 1. 2. 3. 4. 5. 6.]
[ 7. 8. 9. 10. 11. 12.]
[13. 14. 15. 16. 17. 18.]
[19. 20. 21. 22. 23. 24.]
[25. 26. 27. 28. 29. 30.]
[31. 32. 33. 34. 35. 36.]]
2번째 행 전체 원소 출력
[ 7. 8. 9. 10. 11. 12.]
5번째 열 전체 원소 출력
[ 5. 11. 17. 23. 29. 35.]
부분 출력
[[15. 16. 17.]
[21. 22. 23.]
[27. 28. 29.]]
2-2번
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
3번
[[ 0.21862159 2.23607505 -0.56159948 2.0627482 -1.35312291]
[-0.45196089 2.38118527 0.54214996 0.29531398 -1.3756751 ]
[ 0.11210441 1.60344909 0.71672278 1.10790232 0.41659081]
[-1.28873769 -0.26544286 0.01087163 -1.22702418 0.02647448]]
평균 : 0.2603323229168358
합계 : 5.206646458336715
표준편차 : 1.1396837454447413
분산 : 1.298879039630954
최대값 : 2.38118527114613
최소값 : -1.3756751031190795
1사분위 : -0.4793705371100291
2사분위 : 0.16536299941867438
3사분위 : 0.8145176683660762
요소값누적합 : [0.21862159 2.45469664 1.89309716 3.95584536 2.60272245 2.15076156
4.53194683 5.07409679 5.36941077 3.99373567 4.10584008 5.70928917
6.42601195 7.53391427 7.95050508 6.66176739 6.39632453 6.40719616
5.18017198 5.20664646]
| [Python] (8) Numpy 배열 결합 (0) | 2020.06.15 |
|---|---|
| [Python] (6) Numpy broadcasting (브로드캐스팅) (0) | 2020.06.14 |
| [Python] Numpy (5) 집합, 전치 (0) | 2020.06.02 |
| [Python] Numpy (4) - 배열 연산 , 벡터 내적 (0) | 2020.06.01 |
| [Python] Numpy (3) - 슬라이싱 , 서브배열 (0) | 2020.06.01 |
벡터의 내적을 구할 때는 차원이 서로 같아야만 하는 조건이있었습니다.
하지만 이번 브로드캐스트는 다른 차원의 연산이 가능한 점에서 차이가 있습니다.
우선 3가지 방법을 소개해드리면 다음과 같습니다.
1번 for문 // 2번 tile 함수 이용 // 마지막으로 자동 브로드 캐스팅 방법이있습니다.
numpy.empty(배열, dtype='조건')
- 특정한 값으로 초기화하지 않는 배열을 생성
numpy.empty_like(배열, dtype='조건')
- 배열의 크기와 동일하며 특정한 값으로 초기화하지 않는 배열을 생성
import numpy as np
x = np.arange(1, 10).reshape(3,3)
y = np.array([1,0,1])
z = np.empty_like(x)
print(x, end='\n\n')
print(y, end='\n\n')
print(z, end='\n\n')
# x + y
for i in range(3):
z[i] = x[i] + y
print(z, end='\n\n')
# 방법 2 tile()
kbs = np.tile(y, (3,1))
print(kbs, end='\n\n')
z = x + kbs
print(z, end='\n\n')
# 방법 3 nuympy 의 broadcast
mbc = x + y
print(mbc + 100, end='\n\n')
# 출력 결과
[[1 2 3]
[4 5 6]
[7 8 9]]
[1 0 1]
[[1 2 3]
[4 5 6]
[7 8 9]]
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]]
[[1 0 1]
[1 0 1]
[1 0 1]]
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]]
[[102 102 104]
[105 105 107]
[108 108 110]]
x 행렬을 다음과 같이 주고 empty_like 함수를 사용하여 z 행렬을 그대로 복사하였습니다.
이후, 1번 방법 for문을 사용한 경우 각 행의 자리에 맞춰 1차원 배열인 y 값들을 더해 준 것을 확인 할 수 있습니다.
방법 2번 tile을 이용하여 구조를 맞추는 방식으로 3행과 길이는 1로 2차원 배열을 생성한 후 z 배열에 더한 것입니다.
만약 길이를 2로 주었다면 [ 1 0 1 1 0 1 ] 이 3행까지 반복되어서 출력되었을 것입니다.
방법 3번 자동 브로드 캐스팅 사용
자동으로 자리를 맞추어 값을 계산하여 출력합니다.
# broadcast ex
v = np.array([1,2,3])
w = np.array([4,5])
print(np.reshape(v, (3,1))*w, end='\n\n')
print(np.reshape(w, (2,1))*v, end='\n\n')
x = np.array([[1,2,3],[4,5,6]])
print(x, end='\n\n')
print(x+y, end='\n\n')
#print(x+w, end='\n\n') # 브로드캐스팅 불가능
print(x.T , end='\n\n')
print(x.T + w, end='\n\n')
print((x.T + w).T, end='\n\n')
# 출력 결과
[[ 4 5]
[ 8 10]
[12 15]]
[[ 4 8 12]
[ 5 10 15]]
[[1 2 3]
[4 5 6]]
[[2 2 4]
[5 5 7]]
[[1 4]
[2 5]
[3 6]]
[[ 5 9]
[ 6 10]
[ 7 11]]
[[ 5 6 7]
[ 9 10 11]]
1행 3열 배열을 3행 1열로 바꾸어 내적하여 계산하였습니다.
그 다음 라인에서는 w의 1행 2열 배열을 2행 1열로 내적하여 계산하였습니다.
행열의 구조를 변경하는 방법으로 .T 를 사용할 수도 있습니다.
x 행렬은 2행 3열짜리 배열로 구조를 잡아주었습니다.
x.T 를 사용하여 3행 2열짜리의 배열로 구조가 변경 된 것을 확인 하실 수 있습니다.
| [Python] (8) Numpy 배열 결합 (0) | 2020.06.15 |
|---|---|
| [Python] (7) Numpy 배열 행 열 추가 및 삭제 , 내장함수 (0) | 2020.06.15 |
| [Python] Numpy (5) 집합, 전치 (0) | 2020.06.02 |
| [Python] Numpy (4) - 배열 연산 , 벡터 내적 (0) | 2020.06.01 |
| [Python] Numpy (3) - 슬라이싱 , 서브배열 (0) | 2020.06.01 |
